
Neste post iremos falar um pouco dos software que iremos utilizar no nosso teste, iniciando pelo Hadoop e passando por HBase.
1. Apache Hadoop
O Apache Hadoop é, quando buscamos um pouco no Google… uma estrutura que permite o processamento distribuído de grandes conjuntos de dados em clusters de computadores usando modelos de programação simples. Ele é projetado para ampliar de servidores individuais para milhares de máquinas, cada uma oferecendo processamento e armazenamento local. Ao invés de confiar no hardware para oferecer alta disponibilidade, a própria biblioteca é projetada para detectar e lidar com falhas na camada do aplicativo, oferecendo assim um serviço altamente disponível em um cluster de computadores, cada um dos quais podendo ser propenso a falhas.
O HDFS é um sistema de arquivos distribuídos que fornece acesso de alto desempenho aos dados em todos os clusters Hadoop. Como o HDFS normalmente é implantado em hardware de baixo custo, as falhas do servidor são comuns. O sistema de arquivos foi projetado para ser altamente tolerante a falhas, no entanto, facilitando a transferência rápida de dados entre os nós e permitindo que os sistemas Hadoop continuem sendo executados se um nó falhar. Isso diminui o risco de falha catastrófica, mesmo no caso de falhas em inúmeros nós.
Nosso teste usará o Hadoop e seu HDFS como repositório de dados onde vamos salvar e, finalmente, publicar para o aplicativo do usuário final. Você pode ler os recursos do projeto aqui, ou mergulhar na Internet para aprender profundamente sobre isso.
Utilizei o Windows para os meus testes. Os lançamentos oficiais do Apache Hadoop não incluem binários do Windows, mas você pode facilmente criá-los com este ótimo guia (Ele usa o Maven) e configurar os arquivos necessários pelo menos para executar um único cluster de nós. Claro, um ambiente de produção exigirá que configuremos um cluster multi-nó distribuído ou use uma distribuição “apenas para uso” (Hortonworks) ou salte para a Nuvem ( Amazon S3 , Azure, etc…).
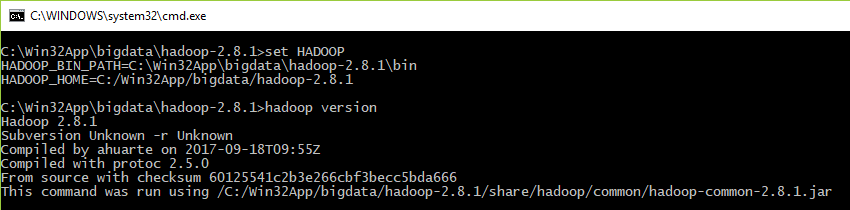
Continuamos com este guia; Depois que o Hadoop foi construído com Maven, os arquivos de configuração foram editados e as variáveis de ambiente foram definidas, podemos testar se tudo está bem executando no console …
> hadoop version
Em seguida, começamos os “daemons” dos objetos namenode e datanode, e o gerenciador de recursos “yarn”.
> call ".\hadoop-2.8.1\etc\hadoop\hadoop-env.cmd" > call ".\hadoop-2.8.1\sbin\start-dfs.cmd" > call ".\hadoop-2.8.1\sbin\start-yarn.cmd"
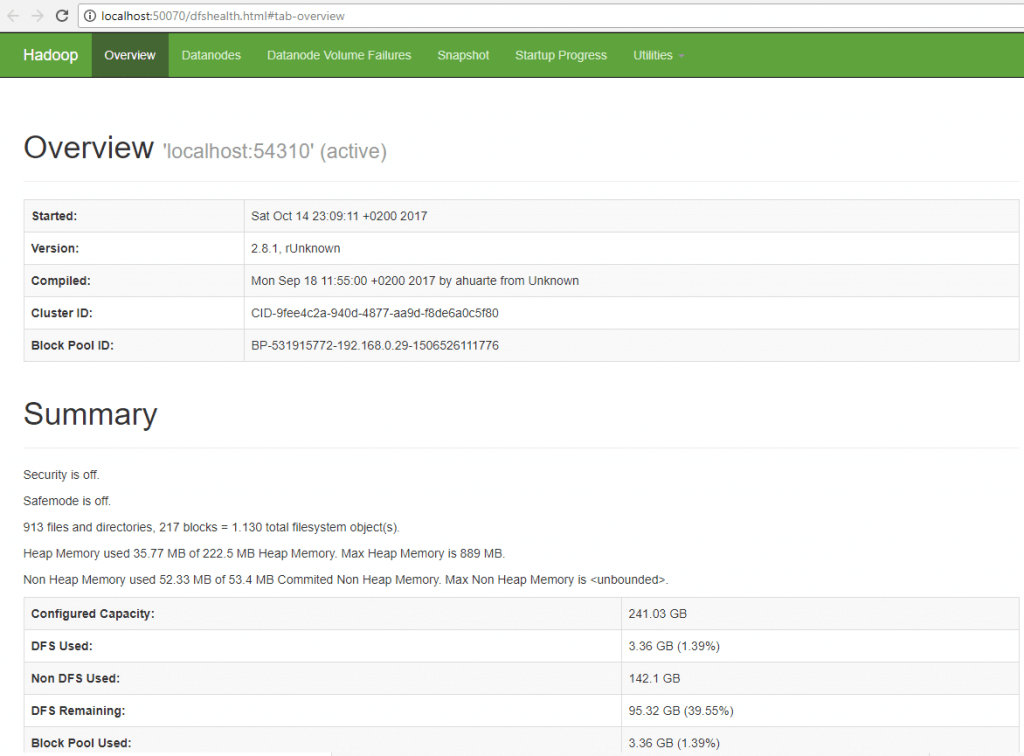
Podemos ver o aplicativo de administração Hadoop rodando na porta HTTP configurada, 50070 no meu caso:
2. Apache HBase
O Apache HBase é, procurando novamente no Google… um banco de dados NoSQL que é executado no topo do Hadoop como um grande armazenamento de dados distribuído e escalável. Isso significa que o HBase pode alavancar o paradigma de processamento distribuído do sistema de arquivos distribuídos Hadoop (HDFS) e se beneficiar do modelo de programação MapReduce do Hadoop. Ele destina-se a hospedar tabelas grandes com bilhões de linhas com potencialmente milhões de colunas e executados em um cluster de hardware de commodities.
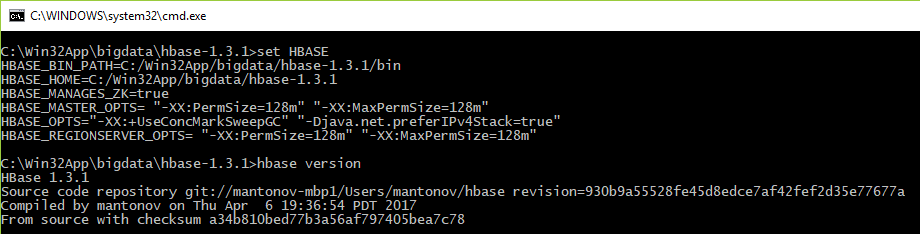
Você pode ler aqui para iniciar e instalar o HBase. Mais uma vez, verificamos a versão do produto executando:
> hbase version
Inicie o HBase:
> call ".\hbase-1.3.1\conf\hbase-env.cmd" > call ".\hbase-1.3.1\bin\start-hbase.cmd"
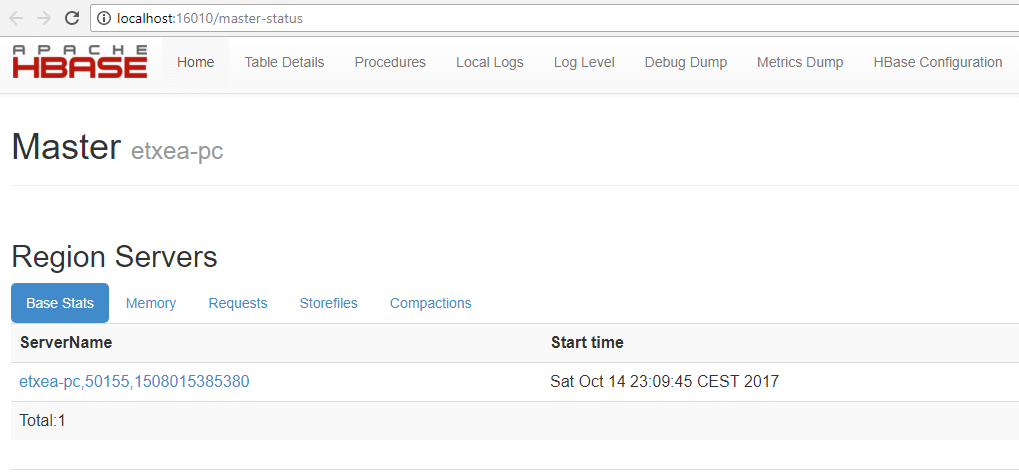
Veja o aplicativo de administração HBase na porta 16010, no meu caso:
Ok, neste momento, temos o grande ambiente de dados funcionando, é hora de preparar algumas ferramentas que acrescentam capacidades geoespaciais; GeoWave e GeoServer, vamos em frente no próximo post…
