
Ao usar ferramentas de software livre para criar aplicativos GIS em um servidor como o GeoServer, você pode ler dados de arquivos e, ao usar mais dados do que arquivos podem armazenar com eficiência, pode ler de um gerenciador de banco de dados como PostgreSQL com PostGIS adicionado para fornecer suporte geoespacial. Se você tiver ainda mais dados, no entanto, você acabará atingindo um limite com o PostGIS. A máquina onde você a instalou pode ter muita memória RAM e espaço em disco, mas escalar a partir daí pode ficar caro se for possível.
À medida que mais tipos de dados se tornam disponíveis para sistemas GIS, está se tornando mais fácil atingir esses limites. O artigo do GIS Lounge “Empowering GIS com Big Data” descreveu algumas das classes de Big Data Spatial que estão levando as pessoas a ultrapassar esses limites e algumas das ferramentas que estão usando para trabalhar com esses dados. Uma ferramenta relativamente nova é o GeoMesa (open source), que adiciona suporte a recursos geográficos aos sistemas de banco de dados baseados no Hadoop Apache Accumulo, Apache HBase e Google Cloud Bigtable. Isso pode permitir que você dimensione o seu uso de dados GIS com sistemas de código aberto.
GeoMesa pode ajudar os usuários a gerenciar grandes conjuntos de dados espaço-temporais, armazenando petabytes de dados GIS e servindo dezenas de milhões de pontos em segundos.
1. Sistemas de banco de dados de Big Data
Primeiro, o que é o Hadoop, o que esses sistemas de banco de dados adicionam a ele e como eles diferem de um banco de dados relacional, como o PostgreSQL? E o mais importante, o que torna essa configuração tão boa para os Big Data Spatial?
O Apache Hadoop é uma estrutura de software livre que originalmente se tornou popular para manipular Big Data devido a dois componentes específicos dessa estrutura: o Hadoop Distributed File System (HDFS), que permite tratar os dados em uma coleção de máquinas comuns como um único sistema de arquivos e o MapReduce, que permite que os aplicativos dividam seu processamento em várias máquinas.
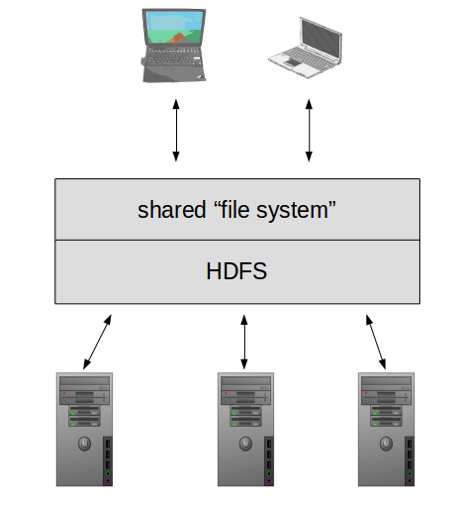
Com essa combinação, um aplicativo com requisitos de recursos crescentes não precisava necessariamente de um computador maior com mais RAM e espaço em disco para aumentar a escala; o crescimento poderia ser tratado pela adição de novas máquinas de baixo custo ao cluster do Hadoop. E, como os recursos baseados em nuvem se tornaram mais fáceis de usar e menos caros, você nem precisa de máquinas físicas permanentes para seu cluster – se você quisesse que doze máquinas funcionassem como um cluster para um trabalho de seis horas, você só precisa ter sua própria “nuvem” dessas máquinas por esse período de tempo.
Isso não funciona com todos os aplicativos, no entanto.
O MapReduce exige que você crie um procedimento Map e um procedimento Reduce para fazer o seu processamento. O procedimento Map é executado em cada nó do cluster, processando o subconjunto de dados transmitidos para esse nó e o procedimento Reduce reúne os resultados das execuções do Map e executa cálculos adicionais para agregar ou resumir os resultados. Esse arranjo funcionou bem para muitos tipos de análises, e as empresas despejaram terabytes de dados em rotinas MapReduce para que pudessem procurar padrões ocultos em seus dados de transações, cliques e registros. No entanto, para aplicativos de banco de dados típicos, a necessidade de dividir o processamento em operações de Map e Reduce dificultava a capacidade de permitir o tipo de consulta interativa e atualização de dados que a maioria das pessoas deseja fazer com seus bancos de dados.
À medida que o Hadoop ganhou força, um desenvolvimento paralelo no mundo da tecnologia da informação foi o desenvolvimento de sistemas de bancos de dados NoSQL. O termo originalmente significava “Não SQL” para descrever sistemas de bancos de dados que usavam alternativas aos modelos de dados baseados em tabela usados com o padrão ISO SQL. O termo evoluiu para significar “Não apenas SQL”, pois aplicações grandes e modernas podem envolver uma coleção de sistemas de banco de dados que usam um modelo de dados diferente para executar uma tarefa especializada, e um sistema SQL – por exemplo, PostgreSQL – pode fazer parte dessa mistura.
Alguns desses sistemas de gerenciamento de bancos de dados NoSQL foram projetados para serem executados em um ambiente Hadoop, onde eles poderiam tirar vantagem do HDFS e proteger os desenvolvedores da necessidade de se preocupar com o Mapeamento e a Redução de seus dados. Uma família particular de bancos de dados NoSQL inspirada no documento Google Big Table sobre como eles armazenam e organizam seus dados é conhecida como “bancos de dados orientados por coluna”. Agrupando os dados de cada tabela por suas colunas em vez de usar a orientação de linha de bancos de dados SQL típicos, esses sistemas de banco de dados adicionaram flexibilidade de modelagem, eficiência de indexação e maior facilidade na distribuição de dados em vários nós.
Três sistemas populares de banco de dados orientados a colunas que podem ser executados no Hadoop são os projetos HBase e Accumulo e o Google Cloud Bigtable, a versão comercialmente disponível do Google do sistema interno de gerenciamento de dados. O conjunto de ferramentas GeoMesa para armazenar, indexar e consultar grandes dados espaciais pode trabalhar com todos esses três sistemas de banco de dados, permitindo que você realize análises geoespaciais em uma escala muito grande. Uma aplicação como o GeoServer pode então usar um repositório de dados GeoMesa como se usasse qualquer outro armazenamento de dados através de sua interface gráfica de usuário baseada na web, através do CQL, ou usando os padrões WFS , WMS , WPS e WCS. Ver essas habilidades adicionadas ao Cloud Bigtable impressionou o Google o suficiente para que eles recomendem o uso do GeoMesa, como um parceiro de serviço.
2. Dados geoespaciais armazenados, streaming de dados geoespaciais
Além de sua capacidade de trabalhar com petabytes de dados geoespaciais armazenados, o GeoMesa pode trabalhar com dados de streaming. Frequentemente, os consumidores de dados de alta velocidade (registros de 10K por segundo ou mais) implementam uma infraestrutura baseada na Arquitetura Lambda. A Arquitetura Lambda tem uma “Camada de Velocidade” para suportar telas interativas e análises quase em tempo real. Os dados armazenados pelo GeoMesa no Accumulo ou HBase fazem parte da camada de serviço que responde às consultas. O GeoMesa também inclui um datastore de streaming baseado no Apache Kafka, que é ideal para suportar reprodução recente em uma visualização de mapeamento. Por exemplo, se o seu sistema estiver lendo dados de posição sobre uma frota de veículos e você quiser renderizar e animá-los em uma camada de mapa, o armazenamento de dados Kafka do GeoMesa pode tornar isso possível. O GeoMesa também pode usar o Kafka para armazenar em cache dados suficientes para permitir que você “retroceda” animações do movimento da sua frota em torno do mapa. Um registro permanente desses dados pode ser fornecido na camada de veiculação para análise forense ou processamento em lote no futuro.
O GeoMesa também pode aproveitar o Apache Spark, uma estrutura de computação que está substituindo cada vez mais o uso direto do MapReduce para processar muito mais rapidamente os clusters do Hadoop. As bibliotecas do Spark para Machile Learning, Streaming e processamento de gráficos também permitem que os desenvolvedores criem e executem aplicativos analíticos mais rapidamente, o que abre algumas grandes possibilidades ao trabalhar com dados espaço-temporais.
A recente versão 1.2 do GeoMesa incluiu uma nova etapa: uma revisão completa pela LocationTech Working Group da Eclipse Foundation. Essa análise garantiu que o código-fonte do GeoMesa e todas as suas dependências estejam em conformidade com as licenças de software amigáveis e sejam compatíveis com a licença Apache v2. Essa revisão completa da propriedade intelectual proporciona às empresas o uso da garantia de software de que podem usá-la com confiança e construir soluções baseadas no GeoMesa.
3. Quem está usando o GeoMesa
Várias forças armadas, agências de inteligência e empresas comerciais dos EUA já estão se beneficiando da capacidade do GeoMesa de ampliar seus Big Data Spatial. Para começar você mesmo, a página inicial da GeoMesa inclui tutoriais, e o YouTube tem vários vídeos que demonstram os recursos da GeoMesa e descrevem sua arquitetura. Para participar das conversas e obter suporte em seu próprio uso do GeoMesa, existem listas de discussão de usuários e desenvolvedores. E, como um projeto de código aberto, você pode entrar e contribuir com a CCRi, LocationTech e dezenas de outros colaboradores.
Fonte: GIS Lounge
