
Durante o ciclo de desenvolvimento do PostgreSQL 11, uma quantidade impressionante de trabalho foi feito para melhorar o particionamento de tabelas. O particionamento de tabelas é um recurso que existe no PostgreSQL há bastante tempo, mas só a partir da versão 10 que ele começou a se tornar um recurso altamente útil. Anteriormente, era afirmado que a herança de tabelas era a implementação de particionamento, o que era verdade. Apenas deixava você fazer o trabalho (e muito) manualmente. Por exemplo, durante INSERTs, se você quisesse que as tuplas cheguem às suas partições, você precisava configurar triggers para fazer isso por você. O particionamento de herança também era lento e difícil de desenvolver recursos adicionais.
No PostgreSQL 10, vimos o nascimento do “Particionamento Declarativo”, um recurso projetado para resolver muitos dos problemas que não eram solucionados com o método de herança antigo de particionamento. Isso resultou em uma ferramenta muito mais poderosa para permitir que você divida horizontalmente seus dados!
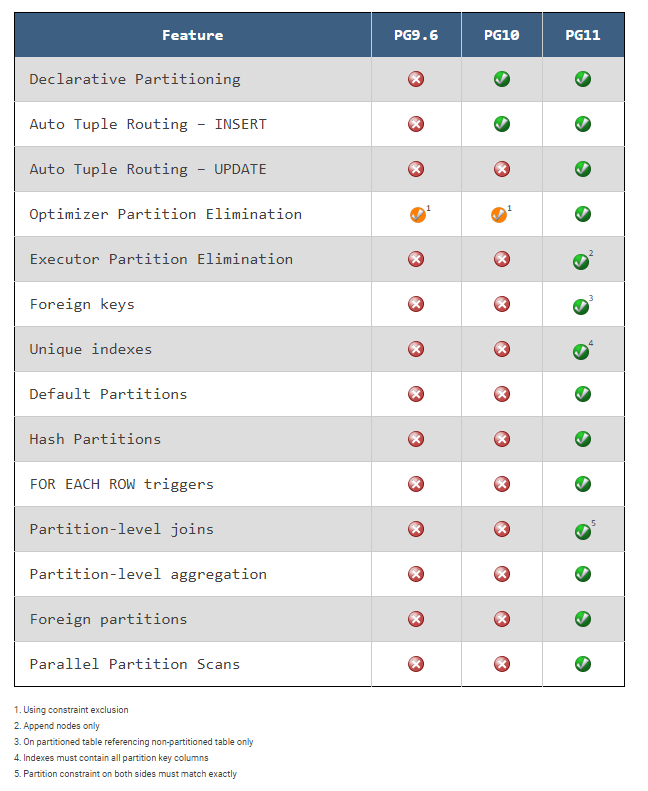
1. Comparação de recursos
O PostgreSQL 11 vem completo com um conjunto impressionante de novos recursos para ajudar a melhorar o desempenho e também para ajudar a tornar as tabelas particionadas mais transparentes para os aplicativos.
2. Performance
Um novo método para realizar o particionamento foi adicionado. Esse novo algoritmo é capaz de determinar partições correspondentes observando a cláusula WHERE da consulta. O algoritmo anterior verificava cada partição, por sua vez, para ver se ela poderia corresponder à cláusula WHERE da consulta. Isso resultava em um aumento adicional no tempo de planejamento à medida que o número de partições aumentava.
Na versão 9.6, com particionamento de herança, as tuplas de roteamento para uma partição eram geralmente feitas escrevendo uma função de trigger que continha uma série de instruções IF para INSERT condicionalmente a tupla na partição correta. Essas funções podiam ser lentas para serem executadas. Com a partição declarativa adicionada na versão 10, isso ficou significativamente mais rápido.
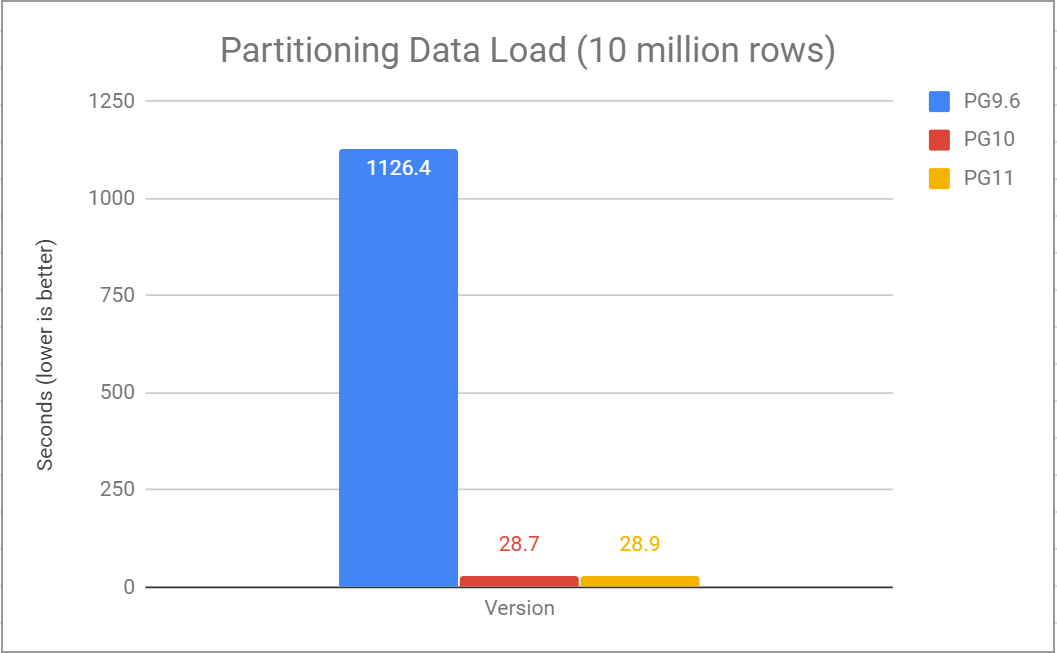
Usando uma tabela particionada com 100 partições, podemos ver o desempenho de carregar 10 milhões de linhas em uma tabela de 1 colunas BIGINT e INT.
Consultando essa tabela para executar uma pesquisa de um único registro indexado e executar o DML para manipular um único registro (usando apenas 1 CPU):
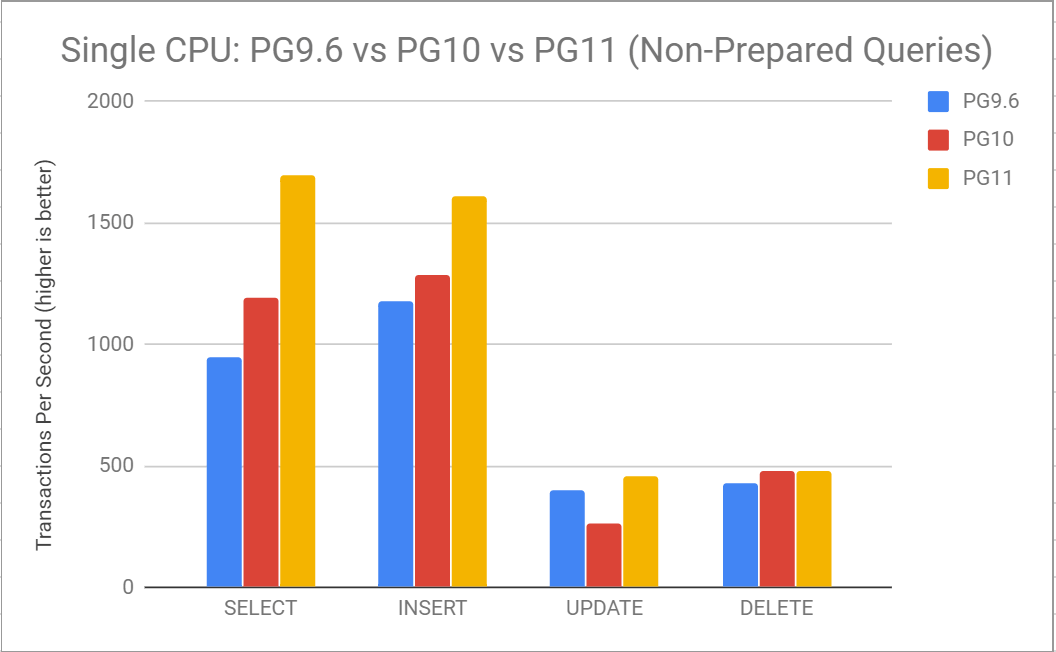
Aqui podemos ver que o desempenho de cada operação melhorou bastante desde o PG 9.6. As consultas SELECT estão parecendo muito melhores, especialmente aquelas que são capazes de eliminar muitas das partições durante o planejamento de consultas. Isso significa que não é mais necessário fazer muito do trabalho que precisava ser feito anteriormente. Por exemplo, não criamos mais caminhos para partições desnecessárias.
3. Resumo
O particionamento de tabelas está começando a se tornar um recurso muito poderoso no PostgreSQL. O particionamento permite que os dados sejam rapidamente colocados on-line e colocados off-line sem a necessidade de esperar pela conclusão de operações DML em massa (lentas). Também significa que os dados relacionados podem ser armazenados juntos, o que significa que os dados necessários podem ser acessados com muito mais eficiência. As melhorias feitas nesta versão não teriam sido possíveis sem os desenvolvedores, os revisores e os committers que trabalharam incansavelmente em todos esses recursos.
Obrigado a todos eles! O PostgreSQL 11 é um lançamento fantástico!
Fonte: Blog 2ndQuadrant
