
A consulta paralela faz parte do PostgreSQL desde 2016 com o lançamento da versão 9.6 e, em teoria, o PostGIS deveria se beneficiar do paralelismo desde então.
Na prática, a natureza complexa do PostGIS significou que pouquíssimas consultas poderiam ser paralelizadas em configurações operacionais normais – elas só poderiam ser forçadas a paralelizar usando configurações ímpares.
Com o PostgreSQL 12 e o PostGIS 3, os planos de consultas paralelas serão gerados e executados com muito mais frequência, devido a alterações nos dois softwares:
- O PostgreSQL 12 inclui uma nova API que permite que extensões modifiquem planos de consulta e adicionem cláusulas de índice. Isso permitiu ao PostGIS remover um grande número de funções SQL embutidas que anteriormente estavam atuando como barreiras de otimização.
- O PostGIS 3 aproveitou a remoção das linhas SQL para re-custear todas as funções espaciais com custos muito mais altos. A combinação de função inlining e altos custos fazia com que o planner tomasse más decisões, mas com as atualizações no PostgreSQL isso agora pode ser evitado.
Aumentar os custos das funções do PostGIS nos permitiu incentivar o planner do PostgreSQL a ser mais agressivo na escolha de planos paralelos.
As funções espaciais do PostGIS são muito mais caras em termos computacionais do que a maioria das funções do PostgreSQL. Um cálculo de área envolve muita matemática envolvendo todos os pontos de um polígono. Uma interseção, reprojeção ou buffer pode envolver ainda mais. Por esse motivo, muitas consultas PostGIS estão com gargalo na CPU, não em I/O, e estão em uma excelente posição para aproveitar a execução paralela.
Uma das funções que se beneficia do paralelismo é a já conhecida ST_AsMVT(). Quando houver linhas de entrada suficientes, a função será expandida e paralelizada, o que é ótimo, pois as chamadas ST_AsMVT () geralmente encerram uma chamada para a dispendiosa função de processamento de geometria, ST_AsMVTGeom() .
Usando a camada Admin 1 de estados e províncias do Natural Earth como entrada, foi executado um pequeno teste de desempenho, construindo um Vector tile para o nível de zoom um.
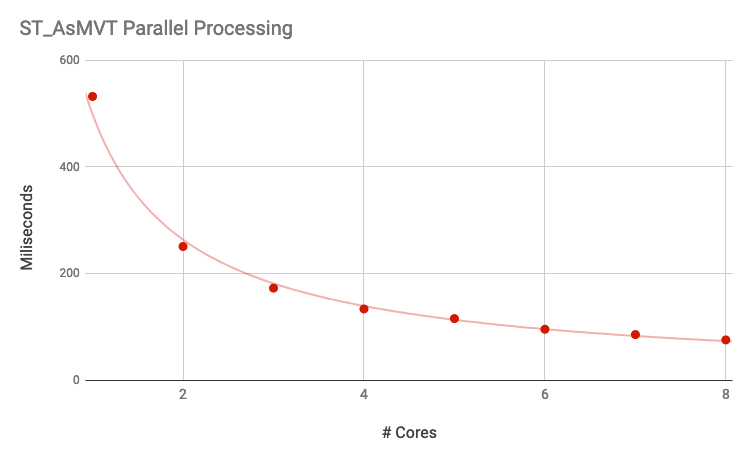
O desempenho das consultas espaciais parece ter uma escala quase igual à não espacial, à medida que o número de núcleos aumenta, levando 30 a 50% menos tempo com cada duplicação de processadores, portanto não linearmente.
A junção, as agregações e as verificações se beneficiam do planejamento paralelo, embora, como os ganhos sejam sublineares, haja um limite para a quantidade de desempenho que você pode extrair de uma operação adicionando mais processadores. Além disso, operações que realizam uma grande quantidade de processamento computacional em uma única chamada de função, como ST_ClusterKMeans, não são paralelizadas automaticamente: o sistema só pode paralelizar a chamada de funções várias vezes, não o funcionamento interno de funções únicas.
Fonte: Clever Elephant Blog
