
Cada dias mais várias empresas e pessoas estão usando as funções Vector Tile do PostGIS como backend para mapas vetoriais dinâmicos, dessa forma qualquer melhoria terá um grande impacto. É por isso que, desde o aparecimento das funções MVT no PostGIS 2.4, elas foram aprimoradas em cada versão principal, e 3.1 não seria diferente.
Como o ST_AsMVT torna realmente fácil extrair informações do banco de dados para o navegador, uma armadilha comum é usar SELECT * para extrair todas as colunas disponíveis que podem mover muitos dados desnecessariamente e gerar blocos extremamente grandes. A solução fácil para esse problema é selecionar apenas as propriedades necessárias para a visualização, mas pode ser difícil aplicá-la retroativamente uma vez que o aplicativo/aplicação já esteja em ambiente de produção e já dependa do design ineficiente.
Ao investigarem o por que o OOM estava interrompendo o bancos de dados, descobriram consultas que estavam usando uma quantidade enorme de recursos para gerar blocos de 50 a 100 vezes maiores do que deveriam (a recomendação é menor que 500 KB).
Neste caso, o mau design de extrair todas as colunas do conjunto de dados foi agravado pelo fato de estar sendo aplicado a um grande conjunto de dados; esse paralelismo do PostgreSQL disparou, exigindo recursos extras para gerar blocos em paralelo e posteriormente mesclá-los.
No PostGIS 3.1 foi então introduzidas várias mudanças para melhorar o desempenho dessas 2 etapas: o processamento paralelo e a fusão de resultados intermediários.
1. As mudanças
Sem entrar em muitos detalhes, o principal benefício veio de alterar o bloco de vetor da forma .proto, para que um recurso possa conter apenas um valor de cada vez. Isso é o que a especificação diz, mas não o que .proto obriga, portanto, a biblioteca interna estava alocando memória que nunca usou.
Existem outras mudanças adicionais, como melhorar a forma como os valores são mesclados entre os workers paralelos, portanto, fique à vontade para dar uma olhada no próprio commit final se quiser mais detalhes.
2. Comparação de desempenho
A melhor maneira de ver o impacto dessas mudanças é por meio de alguns exemplos. Em ambos os casos foi gerado o mesmo bloco, no mesmo servidor e com as mesmas dependências; a única mudança foi substituir a biblioteca PostGIS, que de 3.0 para 3.1.
No primeiro exemplo, o bloco contém todas as colunas dos 287 mil pontos nele. Como mencionado antes, não é recomendável fazer isso, mas é a consulta mais simples de gerar.
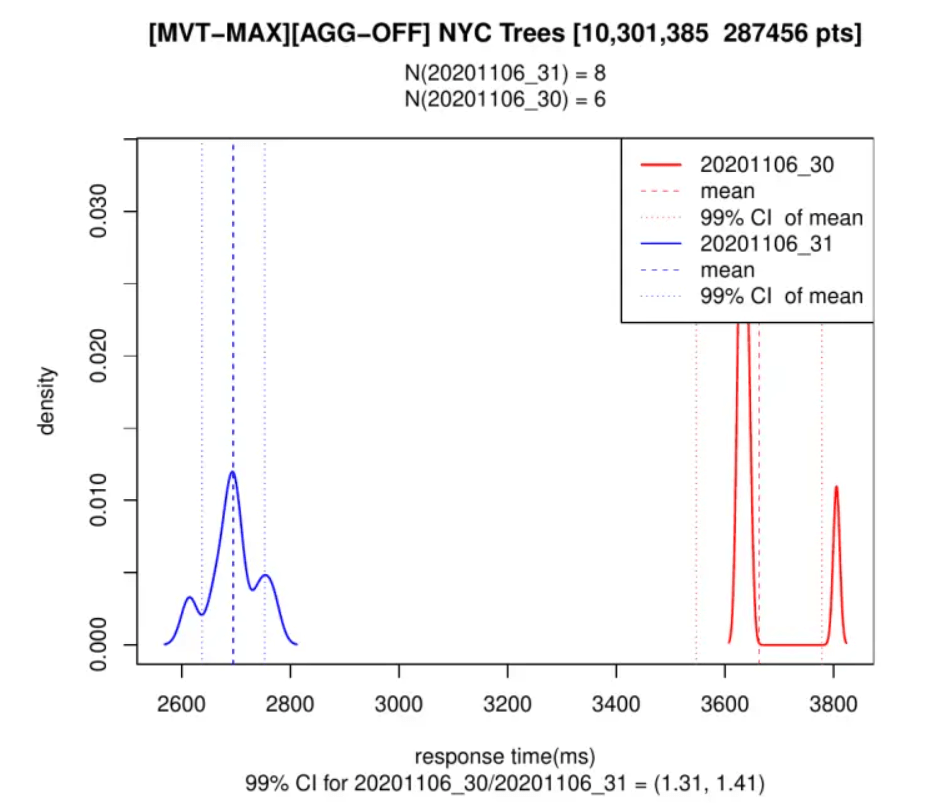
E para o segundo exemplo foi gerado o mesmo bloco, mas agora incluindo apenas as colunas mínimas para a visualização:
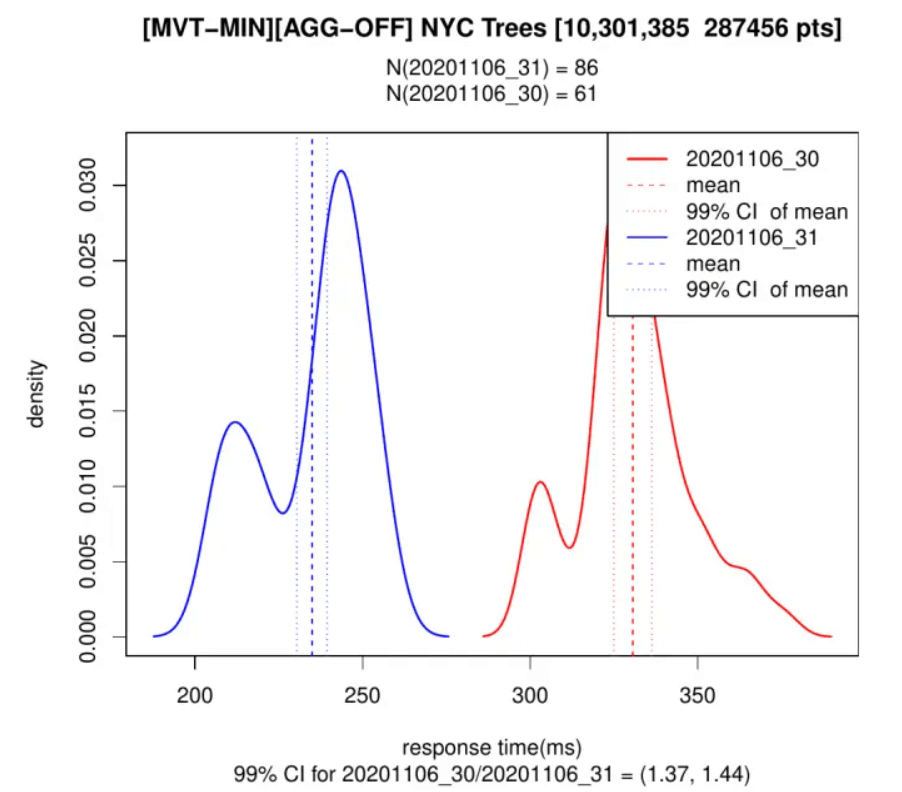
Podemos ver, tanto no PostGIS 3.0 quanto no 3.1, que adicionar apenas as propriedades necessárias torna as coisas 10 vezes mais rápidas do que com os dados completos, e também que o Postgis 3.1 é 30-40% mais rápido em ambas as situações.
3. Uso de memória
Além da velocidade, essa mudança também reduz muito a quantidade de memória usada para gerar um bloco.
Para vê-lo em ação, foi monitorado o processo PostgreSQL enquanto ele está gerando o bloco com todas as propriedades. No 3.0, observamos na linha azul que o uso de memória aumenta com o tempo até atingir cerca de 2,7 GB no final da transação.
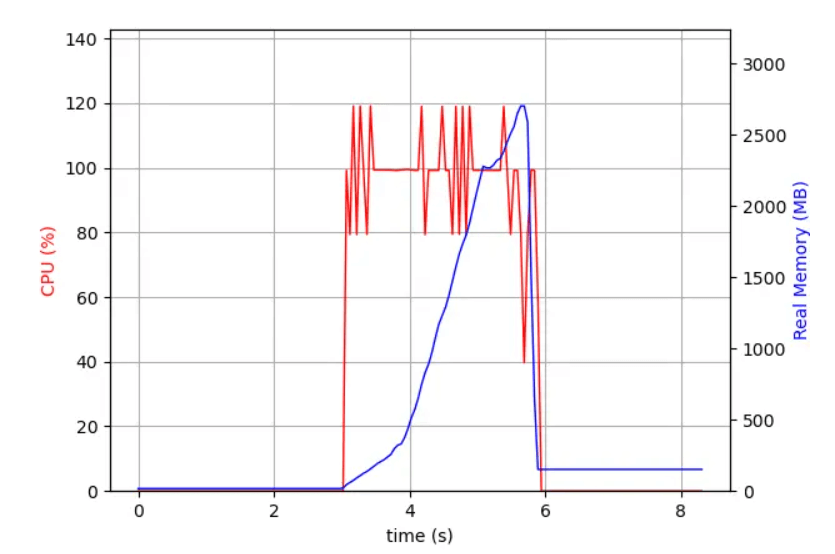
Agora foi monitorada a mesma solicitação em um servidor usando Postgis 3.1. Neste caso, o servidor usa cerca de um terço da memória como no 3.0 (1GB vs 2.7GB) e, em vez de ter um aumento linear, a memória é devolvida ao sistema o mais rápido possível.
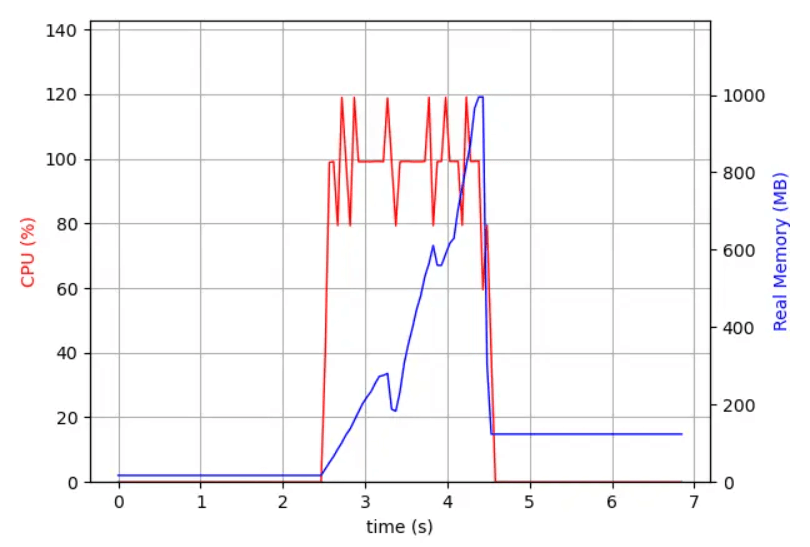
Para resumir tudo: PostGIS 3.1 é mais rápido e usa menos memória ao gerar grandes blocos vetoriais.
Este post foi escrito originalmente escrito por Raúl Marín, e traduzido e adaptado livremente por este blog.
Fonte: Clever Elephant Blog
